Stock Trading with Machine Learning - Backtesting
Once your model is trained on the features, you gotta backtest.
6/28/20253 min read
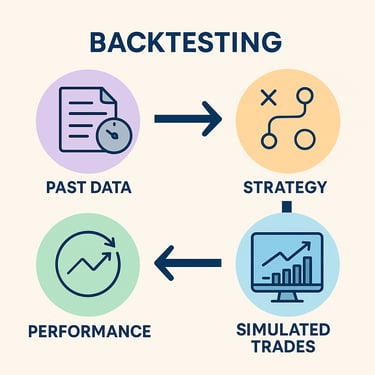
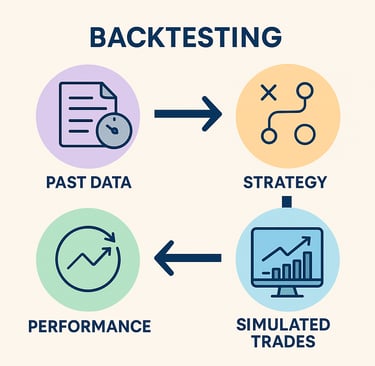
0. What is Backtesting
Picture you’ve invented a new board-game strategy that you think will help you win every time.
Instead of waiting for the next family game-night to try it once, you go back through old score sheets and “re-play” the games on paper using your new moves. If your pretend scores look great, that’s a good sign; if they flop, you need a new plan.
That replay-with-old-data is called backtesting in finance:
Old score sheets → Past stock prices.
Your new strategy → Computer program that decides when to buy or sell.
Pretend replay → The computer steps through each past day, acts out the buys/sells, and tracks the pretend money.
Backtesting answers two questions:
“Did my idea work before?”
“Could I trust it with my real allowance tomorrow?”
Everything else in this post is about making sure those answers are honest—not tricked by peeking at the future or forgetting the cost of trading.
1. Data Integrity Comes First
The runner script starts by verifying that every dependency (CUDA, TA-Lib, XGBoost, LightGBM, yfinance, etc.) is present and working before it touches a single price-bar. raw.githubusercontent.com
Timezone-neutral OHLCV – All indices are localized to naïve timestamps so mixed feeds don’t create ghost gaps.
Column normalization & multi-index fix-ups – yfinance sometimes returns a two-level column index; the loader flattens this so downstream code never has to guess. raw.githubusercontent.com
Leakage validator – A guard class checks that targets are properly shifted and that the requested look-ahead window never overlaps the data used for features.
Take-away – Backtests fail quietly when data are dirty; invest in aggressive sanity-checks up front.
2. Walk-Forward Windows (Train ▶ Validate ▶ Test)
The core config (see optimize_config_for_performance) defines 12 months of training, 3 months of validation, 1 month of out-of-sample test plus a 5-day buffer to guarantee zero look-ahead. The window rolls forward every 21 trading days. raw.githubusercontent.com
Take-away – Use three distinct datasets, always with a buffer, and re-optimize on a cadence that mirrors your future deployment.
3. Point-in-Time Feature Engineering
Inside the test loop the backtester fetches a point-in-time slice of history for each symbol, generates 400-plus indicators, then makes a prediction only if the feature row exists for that date. If the row is missing (e.g., IPOs), the symbol is skipped so you never peek into the future. raw.githubusercontent.com
4. Signal Generation & Risk Gating
For every business day in the test set:
Update open positions (stop-loss, take-profit, time exit).
Create new signals: only symbols not already held, confidence ≥ 0.60, sorted highest-to-lowest.
Position sizing: risk-parity × confidence, checked against portfolio “heat” and sector caps.
Skip anything smaller than $1 k to keep frictional costs realistic. raw.githubusercontent.com
5. Execution Simulator: Making Paper Alpha Pay Rent
Realistic fills are the difference between fantasy and reality. Each order passes through:
Commission model – per-share plus min/max guards.
Spread-based slippage – 5 bp baseline, scaled up at the open/close.
Square-root market impact – penalizes anything > 10 % ADV.
Limit-order fill probability – defaults to 85 % and improves the closer your price is to the inside quote. raw.githubusercontent.com
Take-away – If you don’t model costs, you’re testing a signal, not a strategy.
6. Daily Book-Keeping
Every loop stores:
Cash, open-positions count, portfolio value
Trade logs (date, action, shares, price, commission, slippage, reason)
Equity-curve point – used later for drawdown and rolling-Sharpe charts
This data is kept in plain Python lists so the backtest can be JSON-serialized without fuss. raw.githubusercontent.com
7. Final Metrics & Reporting
At the end of the walk-forward run the backtester computes:
Total & annualized return
Sharpe, Sortino, max drawdown
Win-rate, profit factor, average win/loss
Symbol-level stats so you can see who really pulled their weight
Plots (equity, drawdown, rolling Sharpe, position count, monthly returns, P&L distribution) are generated with a single helper call. Results are dumped to JSON + TXT for easy ingestion into dashboards. raw.githubusercontent.com
8. Quick vs. Full-Watchlist
test_simple_backtest.py – 5 FAANG symbols, two-year span, minimal rules; finishes in minutes and proves the pipeline is wired correctly. raw.githubusercontent.com
test_and_run_backtest.py – CLI menu to launch either the smoke test or the 198-symbol, GPU-powered walk-forward run. raw.githubusercontent.com
Take-away – Maintain a fast test you can run on every commit, and a slow test you run before shipping research to production.
9. Design Principles for a Robust Backtester
Deterministic data – Freeze raw data snapshots, log data-vendor versions.
No-look-ahead, no-survivorship – Use delisted symbols & historical index memberships when possible.
Repeatable configs – Every hyper-parameter is stored in one dataclass so tomorrow’s run is comparable to today’s.
Realistic frictions – Model at least commission, spread, impact, borrow costs (if shorting).
Walk-forward, not walk-back – Only the past should influence the future at each step.
Stat-sig, not just point-estimates – Bootstrap or Monte-Carlo your equity curve to understand variance.
Automated health-checks – Validate environment, features, and leakage before any capital is simulated.
Jared Vogler
industrial engineer
Location
Charleston, South Carolina